The Jallikatu Protest
02 Feb 2017The Jallikatu Protest was the worlds largest peaceful protest to protect the culture of Tamil Nadu’s legendary bull ‘hugging’ festival. Around five million people gathered at the Marina Beach to show their support in continuing the game despite discouragement by the government. There was hardly a Chennaite who didn’t show up at the beach, me included.
It was quite interesting to watch the protest seep into social media. And where there’s social media, there’s data. In abundance!

Gathering Data
There were clearly two separate groups, those who were pro-jallikatu and those who were pro-peta. This provided the first divergent for my data. I collected 3000 tweets evenly distributed from Jan 11th to Jan 21st, 2017 that contained either one of two hashtags - #banpeta and #banjallikattu.
Unfortunately the Twitter API has a search limit. The API only allows an indexed access to the past 7 days of tweets. Thankfully there’s always a work around, I found a really nice script that allows this, Jefferson-Henrique/GetOldTweets-python.
Normalizing Data
Tweets are never the ideal data set. They’re riddled with ‘alternative’ spellings, ridiculous hashtags and sprinkled with links and retweets. In fact, a few tweets were just hashtags! That’s it. We had to gather again and limit tweets with only less than 3 hashtags.
We then removed punctuation, hashtags, mentions, URLs, smileys and ‘alternative’ spellings.
Choosing Classifiers and Feature Extractors
Naveen and I then split the data into 700 for training, 300 for testing and the rest for validation data. With the 700 tweets we trained a classifier that puts tweets with #banpeta in the ‘positive’ bucket and those with #banjallikattu in the ‘negative’ bucket. We considered three classifiers - Naive Bayes, Decision Tree and Support Vector Machine. And two feature extractors, Bigrams (fallback to Unigrams) and WF-MFS.
WF-MFS (Word Frequency - Manual Feature Segregation)

This is a feature extractor that we’re still working on here at Skcript. The simple logic being, create a TF-IDF vector and pick the top N frequent feature words (we chose N to be 200). Then choose the compliment words based on the classification. (Ignore the words that were common between the positive and negative tweets, consider a unique mix of the compliment and popular feature words). The second part requires manual reinforcement, though we were able to automate it to a certain degree.
Here were the feature words we chose,
{
'contains_animal' : bool(re.search('animal.|cruel*', sentence, re.IGNORECASE)),
'contains_bull' : bool(re.search('save [a-zA-Z]* bull', sentence, re.IGNORECASE)),
'contains_torment' : bool(re.search('torment|tortur*', sentence, re.IGNORECASE)),
'contains_save' : bool(re.search('save', sentence, re.IGNORECASE)),
'contains_yoddha' : bool(re.search('yoddhas?', sentence, re.IGNORECASE)),
'contains_disgrace': bool(re.search('disgrace', sentence, re.IGNORECASE)),
'contains_brain' : bool(re.search('brain*', sentence, re.IGNORECASE)),
'contains_profanity' : bool(re.search('barbar*|ruthless',sentence, re.IGNORECASE)),
'contains_midnight' : bool(re.search('mid[/-]*night?',sentence, re.IGNORECASE))
}
We then trained the three classifiers on these two feature extractors. Here’s what we found!
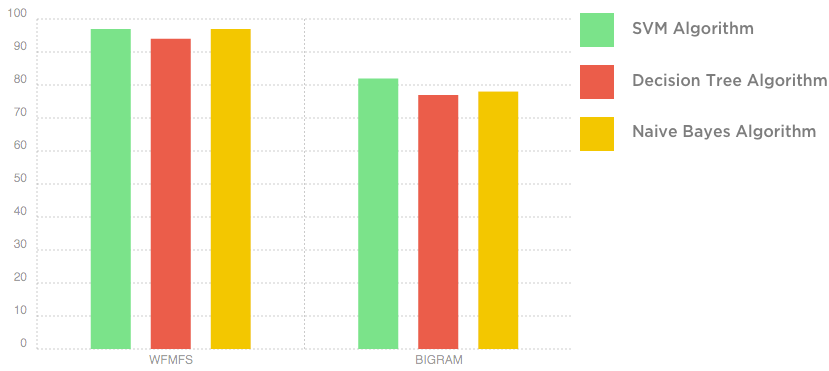
Sentiment Classification
We then ran the classifier on the validation data, in two different ways.
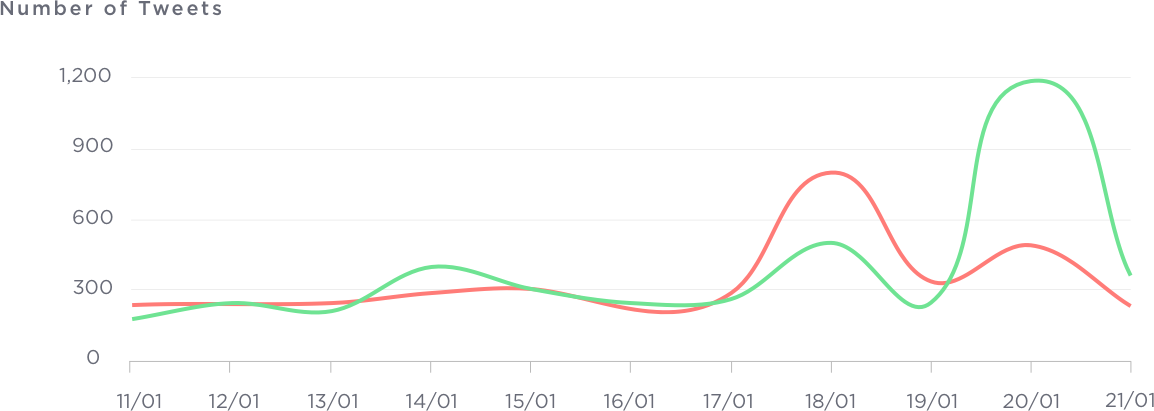
Day By Day Sentiment Analysis
The protest slowly picked up interest on social media and peaked on a 18th and 20th of January. These were the most crucial days of the PCA bill. You can see an almost flip of negative and positive sentiments on these days. When the ordinance was finally passed on the 20th there was a peak of positive tweets. Unfortunately the days leading up to that weren’t so great.
Hashtag Sentiment Analysis
Another interesting study was to see the sentiment of people pro-jallikatu and pro-peta. It was welcoming to see that people supporting Jallikatu were quite positive with their tweets. Quite the hallmark for the peaceful protest! :)
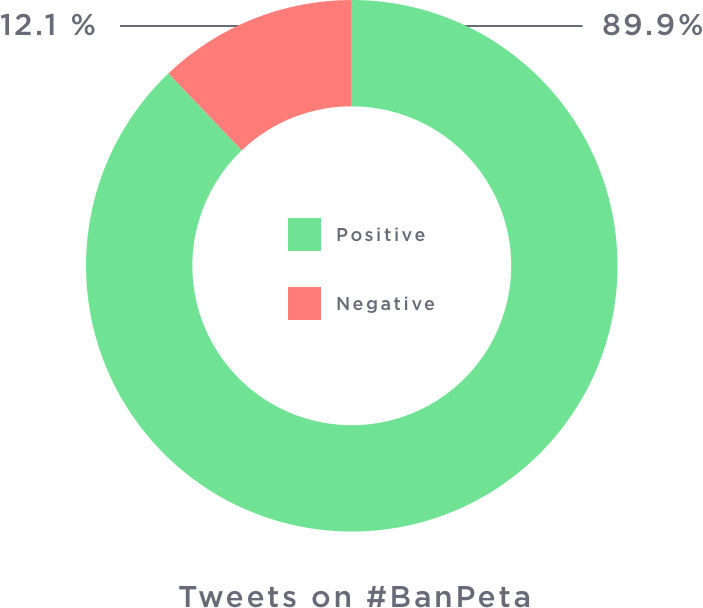
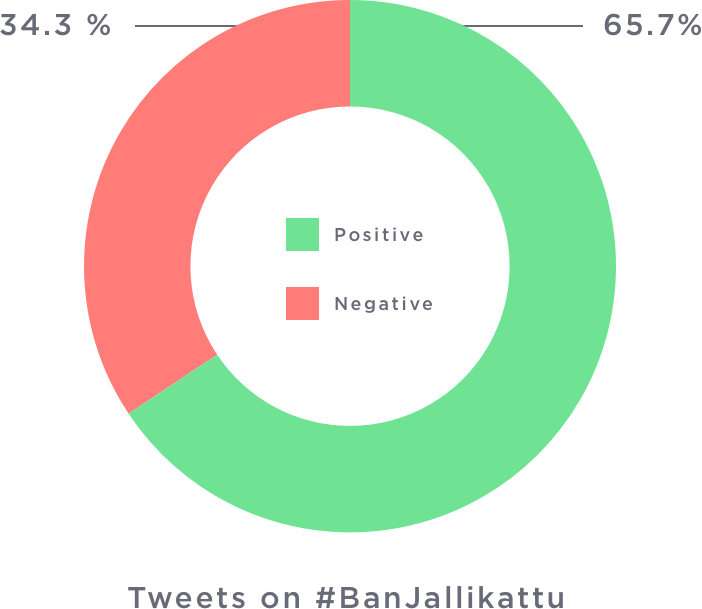
One More Thing
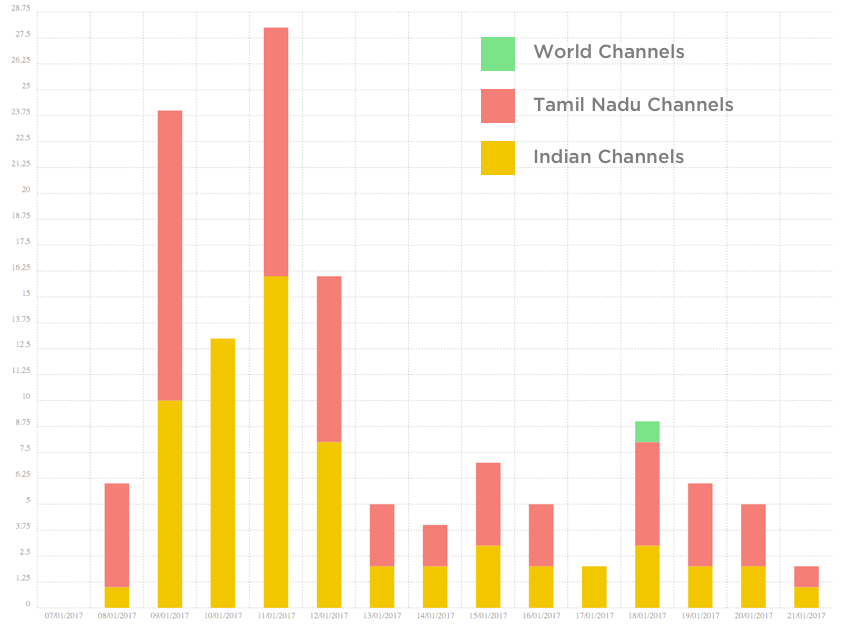
There was a lot of backlash that national media was hardly covering anything on the peaceful protests. We wondered if this sentiment was accurate or not. So we took the Twitter profiles of popular news networks, and saw the frequency of their coverage from Jan 11th to Jan 21st.
Here’s where we sourced the data from,
Tamil Nadu Channels
World Channels
Indian Channels
What do you think about the coverage? ;)